Beyond the Blue Link: Mastering RAG in the Age of AI Search
Imagine looking at your analytics dashboard to find that your keyword rankings are perfectly stable, but your actual website conversions are quietly drifting downward.
Your traditional SEO metrics show green lights, yet your inbound traffic and leads are shrinking because your audience has stopped clicking through to traditional results pages. As user behavior shifts toward conversational platforms like ChatGPT, Perplexity, and Gemini, the old goal of ranking on Google’s first page is losing its impact. Recent data reveals that holding the number one position on a standard Google page now only translates to a 31.4% AI mention rate. Drop to the fourth spot, and your visibility inside AI answers plummets to a mere 2.6%.
The search landscape has permanently split. To maintain visibility, you must pivot your strategy away from traditional keyword optimization and move toward AI Retrieval Optimization.
The Core Engine: What is RAG?
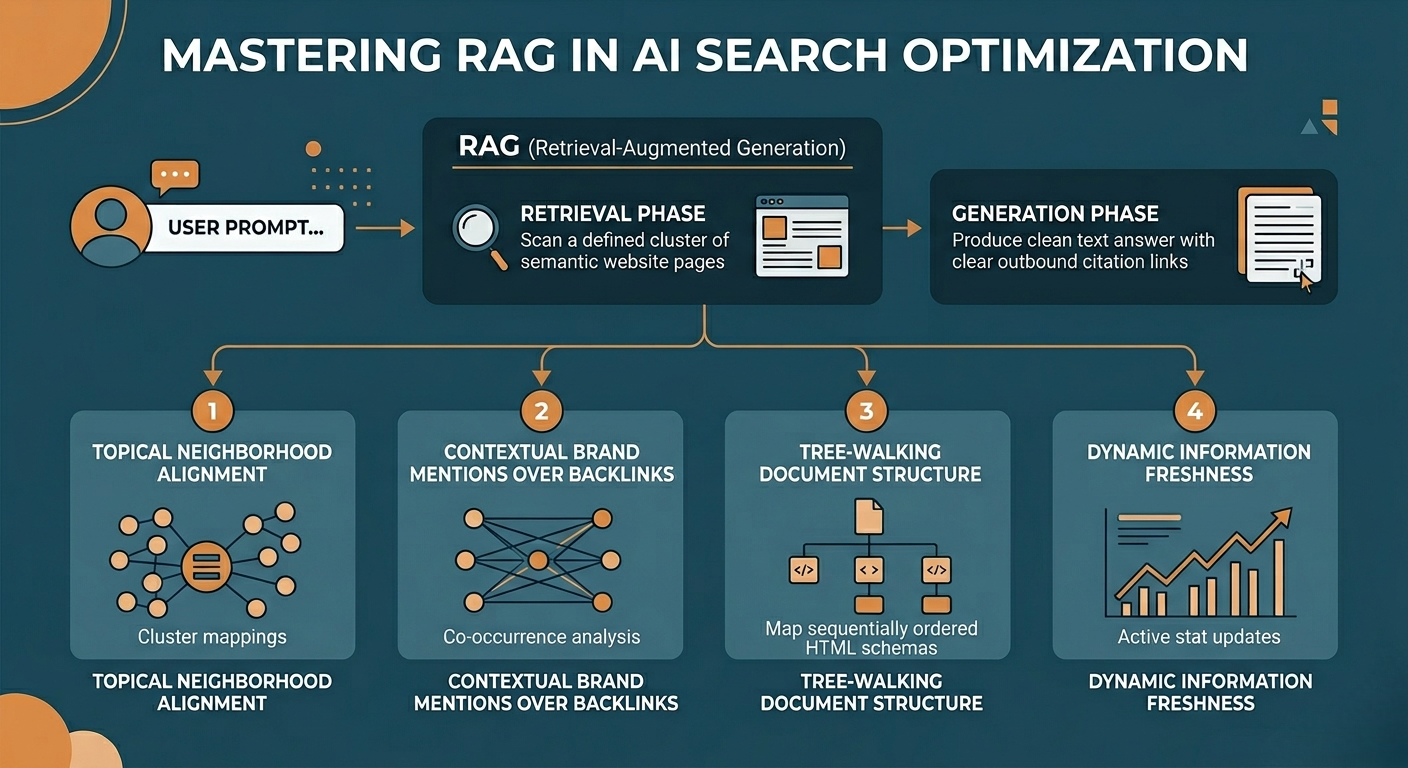
Unlike traditional search engines that serve a directory of links, AI engines utilize a technical framework known as RAG (Retrieval-Augmented Generation). When a user asks a question, the system executes its work in two real-time phases:
-
1. The Retrieval Phase: The AI scans the web for a small, trusted pool of highly authoritative documents. If your page is missed here, you do not exist in the final answer.
-
2. The Generation Phase: The AI synthesizes the retrieved data into a natural response and produces the final response with clear outbound citation links.
The primary objective of modern digital optimization is survival through the Retrieval Phase.
The 4 Signals Evaluated by AI Crawlers
When an AI crawler assesses your website to determine whether it deserves to be retrieved, it looks past keyword density and calculates four specific signals:
-
Topical Neighborhood Alignment: AI models categorize information into contextual clusters. They evaluate whether your brand legitimately operates within a specific niche. A financial firm publishing an analysis on corporate tax updates fits a logical neighborhood; a lifestyle blog publishing that exact same analysis triggers an anomaly and gets filtered out.
-
Contextual Brand Mentions Over Backlinks: In AI search, unlinked branded mentions on trusted sites show a stronger correlation with high retrieval rates than standard backlinks or domain rating metrics. The AI tracks how frequently your brand name appears alongside specific industry topics across the web.
-
Tree-Walking Document Structure: AI web crawlers analyze your layout files using tree-walking algorithms that navigate your code sequentially from top to bottom. If your HTML is structurally cluttered or lacks logical headings, the system cannot parse your answers cleanly.
-
Dynamic Information Freshness: Conversational platforms exhibit a strong preference for highly current data, particularly within fast-moving business sectors. Maintaining updated market statistics, modern case studies, and refreshed publication timestamps is essential.
Re-Engineering Content for Machine Extraction
Language models process long-form content by breaking text down into small, distinct sections known as “chunks.” If your core data point or answer is buried deep within paragraph 15 of a long essay, the system’s chunking process will likely discard it.
Key Structural Requirements:
-
Adopt the Inverted Pyramid: State your absolute conclusion or answer in the opening sentence of a section, then utilize the subsequent paragraphs to provide supporting context.
-
Build Modular Sub-sections: Ensure every sub-header introduces a standalone block of information that can be extracted and understood completely on its own.
-
Use Clean HTML Schemas: Rely on standard
<h2>and<h3>tags, clean unordered bulleted lists, and structured FAQ formatting blocks.
The Multi-Platform Discovery Reality
The digital landscape is no longer a search monopoly. Discovery has fragmented across multiple distinct software applications, each with unique algorithms and referral patterns:
-
ChatGPT: 1.22 Billion Users | Captures 78% of LLM referral traffic.
-
Gemini: 750 Million Users | Captures 12% of LLM referral traffic.
-
Perplexity: Built for high-intent research with a heavy reliance on direct citations.
Relying on traditional Google indices to feed these platforms is no longer enough. Previously, the top results on Google accounted for nearly all conversational citations. Today, 75% of all AI citations originate from entirely non-Google sources, drawing instead from direct brand sites, developer repositories, and active niche forums.
Four Immediate Steps to Protect Your Traffic
-
Audit Your Robots.txt File: Immediately check
yourdomain.com/robots.txt. Data shows that nearly 6% of commercial websites accidentally block major AI crawlers likeGPTBotandPerplexityBot, making them completely invisible to conversational engines. -
Execute Topical Clustering: Stop producing broad, surface-level articles on disjointed topics. Identify a specific operational challenge within your niche and construct deep, highly interconnected content clusters that cover every dimension of that single problem.
-
Drive Contextual PR Campaigns: Focus on securing clear brand mentions on the authoritative third-party networks where AI engines pull their reference texts – including respected trade journals, industry podcasts, and verified community forums.
-
Establish an Asset Refresh Cycle: Set a routine schedule to update your top-performing pages. Replace outdated industry statistics with current data, inject recent case studies, and update page architectures to maintain dynamic freshness.